[1] 4.14[1] 6.28[1] 1.772005[1] 1.144223[1] 9.8596PLS 206 — Applied Multivariate Modeling
2026-01-01
Run code: Cmd+Enter (Mac) / Ctrl+Enter (Windows)
$ctrl
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.170 4.550 5.155 5.032 5.293 6.110
$trt1
Min. 1st Qu. Median Mean 3rd Qu. Max.
3.590 4.207 4.550 4.661 4.870 6.030
$trt2
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.920 5.268 5.435 5.526 5.735 6.310 ggplot(PlantGrowth, aes(group, weight, fill = group)) +
geom_boxplot(alpha = 0.75, show.legend = FALSE) +
geom_jitter(width = 0.08, alpha = 0.6) +
labs(title = "Raw values (ANOVA)") +
theme_classic()
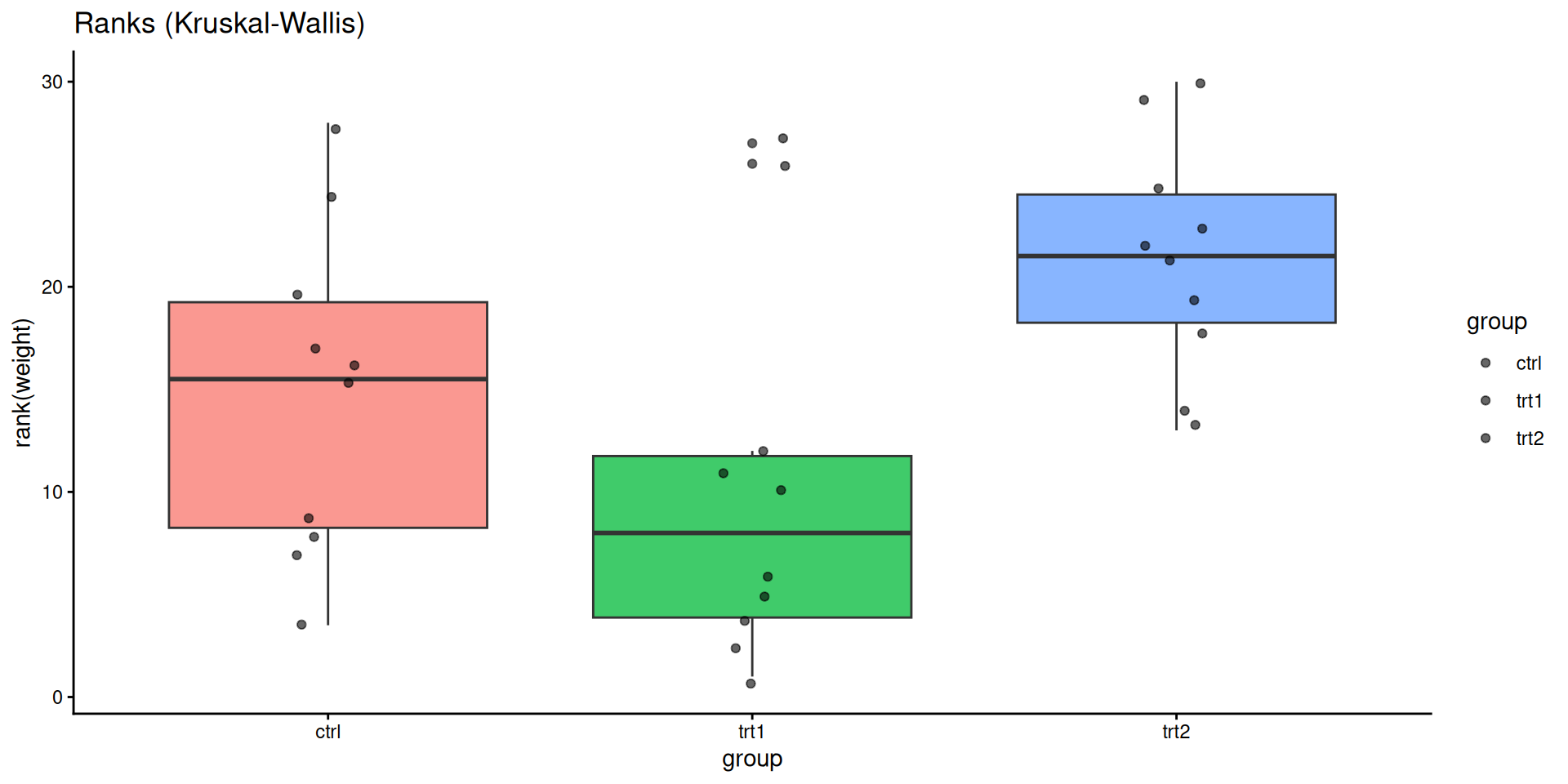
ggplot(PlantGrowth, aes(group, rank(weight), fill = group)) +
geom_boxplot(alpha = 0.75, show.legend = FALSE) +
geom_jitter(width = 0.08, alpha = 0.6) +
labs(title = "Ranks (Kruskal-Wallis)") +
theme_classic()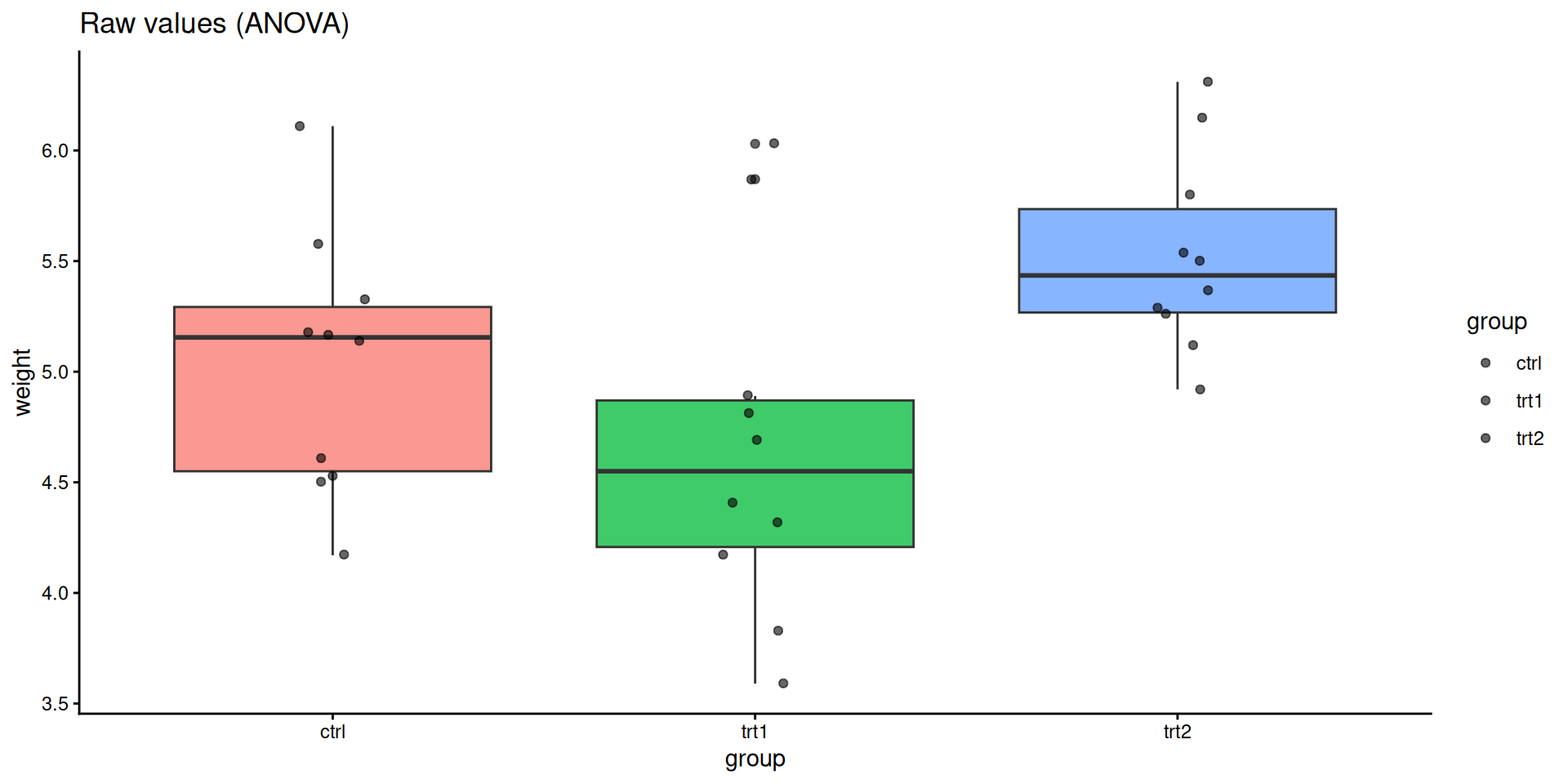
ggplot(sub, aes(conc, uptake)) +
geom_point() +
geom_smooth(method = "lm", linewidth = 0.8) +
geom_smooth(method = "loess", linetype = 2, linewidth = 0.8) +
labs(title = "Raw", x = "CO2 concentration", y = "Uptake") +
theme_classic()
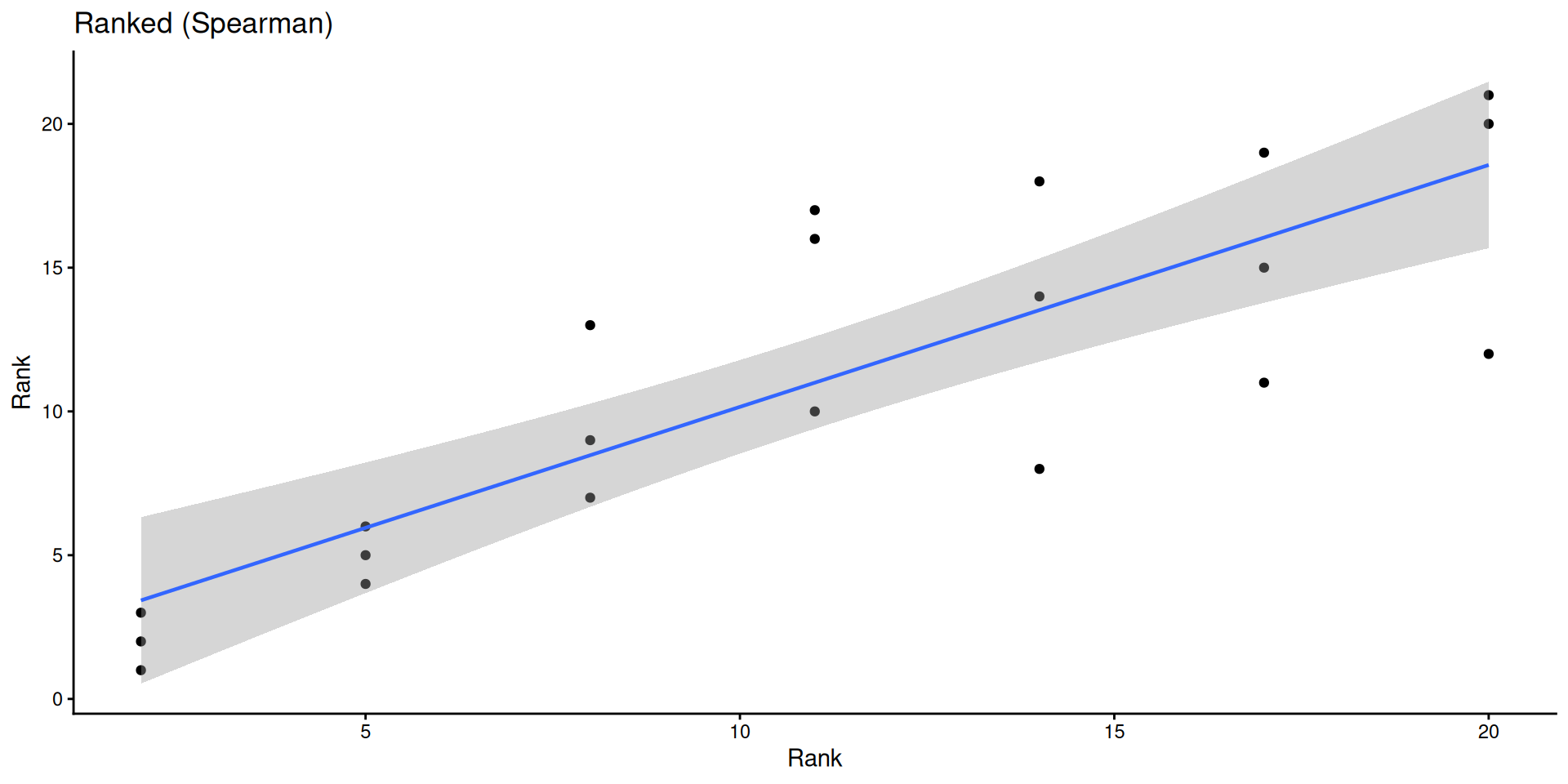
ggplot(sub, aes(rank(conc), rank(uptake))) +
geom_point() +
geom_smooth(method = "lm", linewidth = 0.8) +
labs(title = "Ranked (Spearman)", x = "Rank", y = "Rank") +
theme_classic()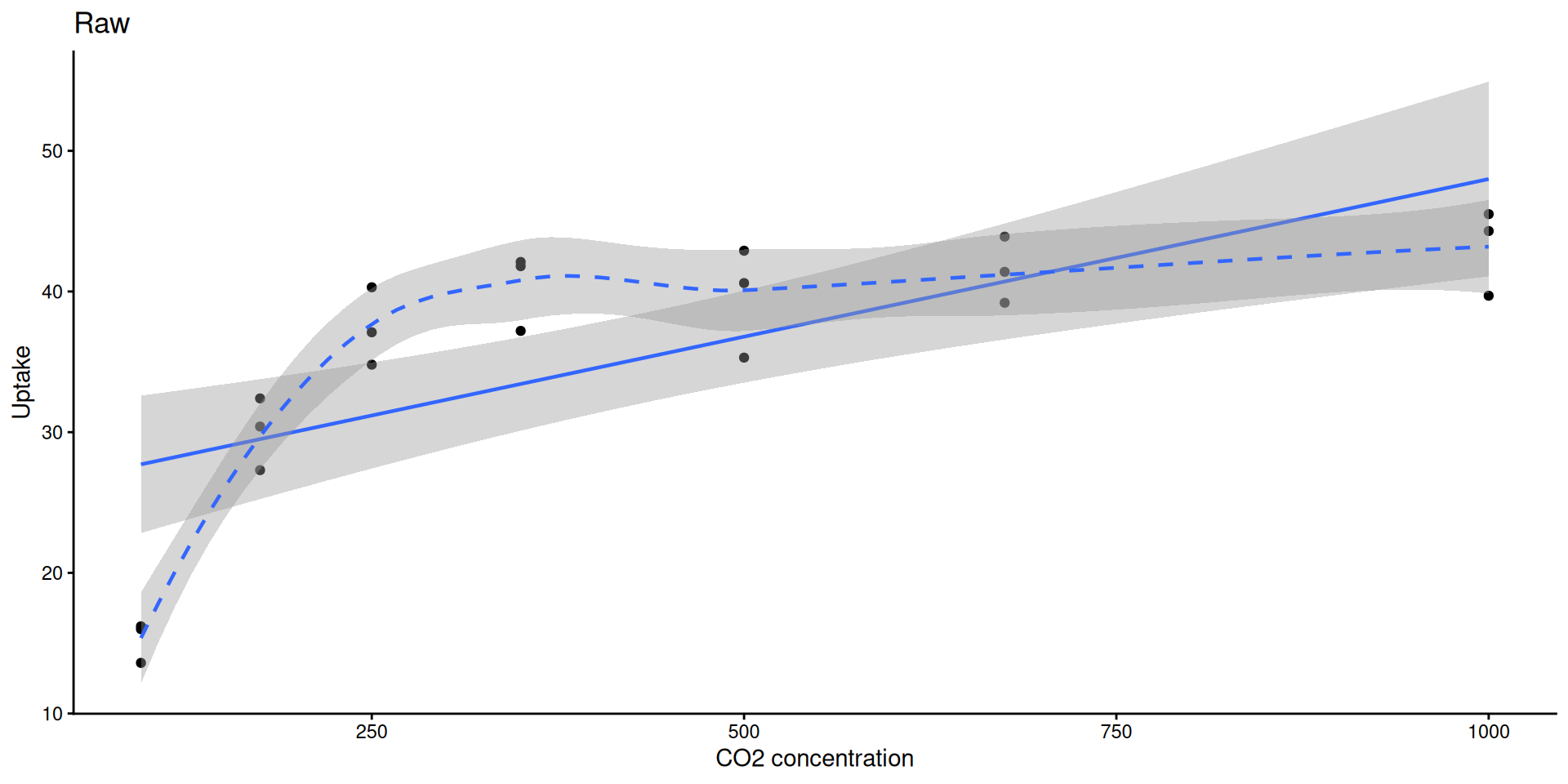
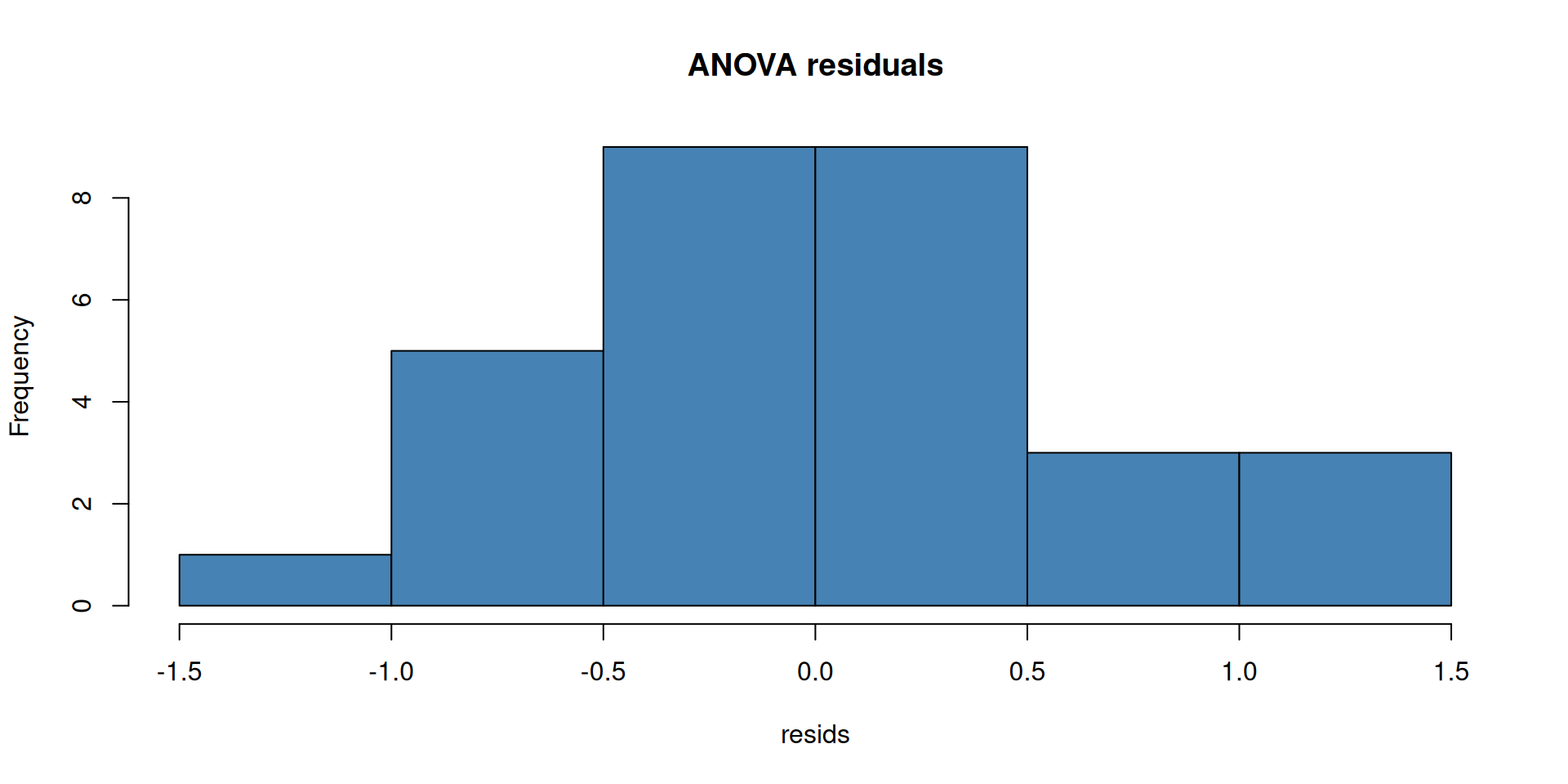
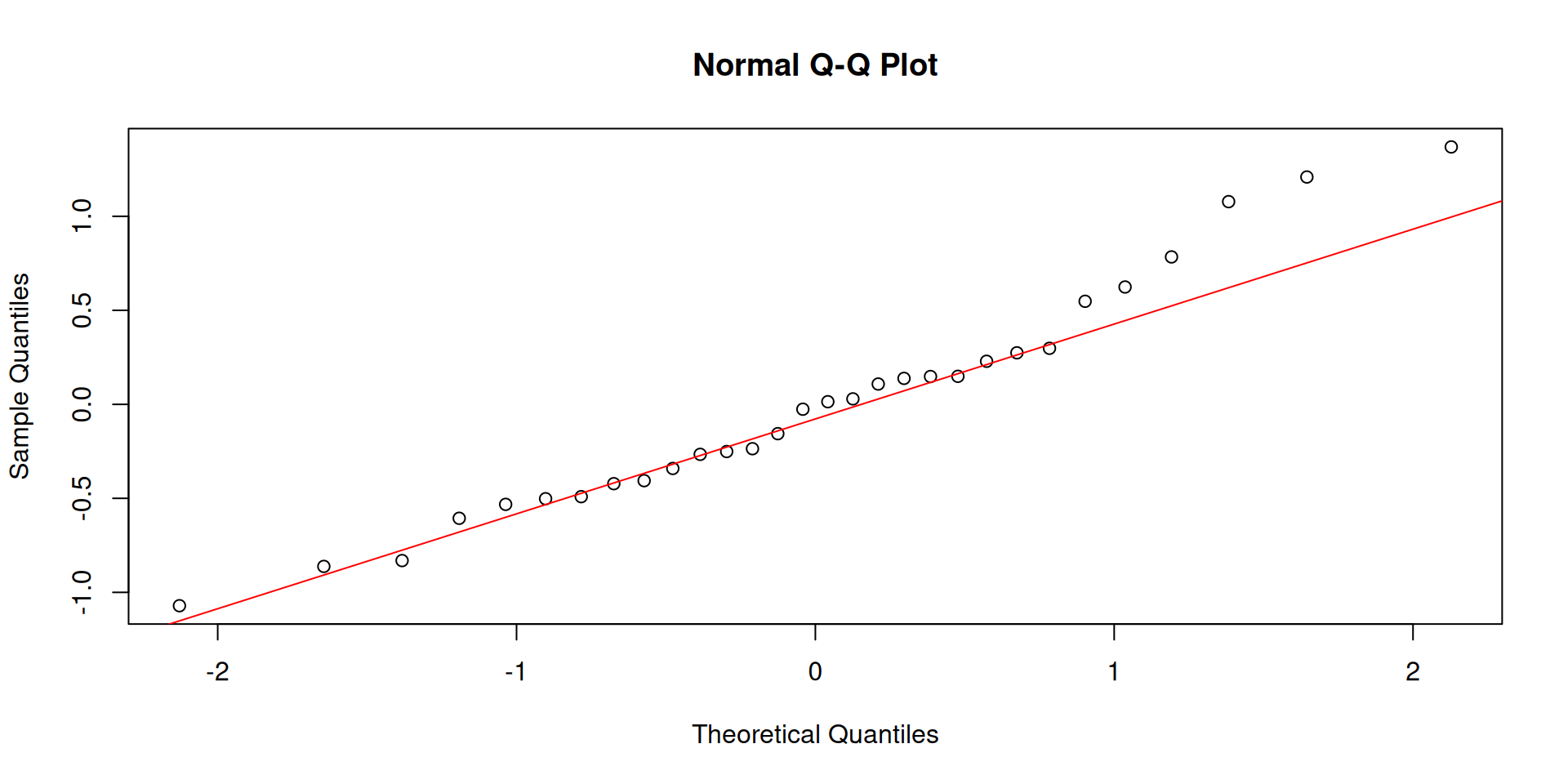
Always check your residuals, not the raw data: